Mohak Bhardwaj

I am a Research Scientist at Boston Dynamics where I work on machine learning for dexterous manipulation (video) and whole-body control (video) for the Atlas robot.
I earned my Ph.D. in Computer Science from University of Washington advised by Byron Boots. My thesis explored topics like improving model-predictive control with RL, accelerating motion planning with imitation learning, and offline reinforcement learning. During my Ph.D. I also had the great opportunities to intern at Google DeepMind, London and NVIDIA’s Seattle Robotics Lab.
Before transferring to University of Washington, I spent a year as a Ph.D. Robotics student at Georgia Tech. Prior to that I was a Robotics Engineer at Near Earth Autonomy. I earned my Master’s from the Robotics Institute from Carnegie Mellon University and B.Tech in Mechanical Engineering from Indian Institute of Technology (BHU), Varanasi.
In my free time, I enjoy to travelling, learning new languages, performing stand-up and improv comedy and practicing Capoeira.
News
June 2025 - I gave an invited talk in the Robotics Seminar at Ehime University, Japan.
May 2025 – Neel presented our paper on combining offline value function learning with MPC at ICRA 2025 (link).
April 2025 – Our work on learning visuomotor policies for dexterous manipulation with eAtlas was featured in a public video release (link) and NVIDIA Developers Technical Blog (link).
March 2025 - Video released of our work on whole body control using reinforcement learning with eAtlas (link).
April 2024 – I moved to Cambridge, MA to start a new job as a Research Scientist on the Atlas team at Boston Dynamics!
March 2024 - I successfully defended my PhD thesis titled When Models Meet Data: Pragmatic Robot Learning with Model-based Optimization at University of Washington.
Selected Research
Dynamic Manipulation with MPC + Offline RL

We developed a method to teach robot manipulators the dynamic non-prehensile waiter's task by combining a pessimistic value estimate learned via offline RL from demonstrations with online MPC. Published at ICRA 2025. [Paper] [Website]
Adversarial Model-based Offline RL

We derive an adversarial model-based offline RL algorithm with theoretical guarantees on policy improvement that is robust to hyperparameter settings and exhibits strong empirical performance. Published at NeurIPS 2023. [Paper] [Proceedings][Website]
STORM: A GPU Accelerated MPC Framework

We develop a system for sampling-based MPC for manipulators that is efficiently parallelized using GPUs. Our approach handles task and joint space constraints at a high control frequency (~125Hz), and integrates perception with control by utilizing learned cost functions from raw sensor data. Published at CoRL 2021 (selected for oral talk - 6% acceptance) [Paper][Website][Code][Talk]
Blending MPC and Value Function Learning

We develop a framework for improving on MPC with model-free RL that can systematically trade-off learned value estimates against the local Q-function approximations. Published at ICLR 2021.[Paper]
Learning Graph Search via Imitation Learning

We formulate lazy graph search as an MDP and develop a framework for learning efficient edge evaluation policies by imitation oraculaor planners. Published at RSS 2019. A version of this line of work was selected as a finalist for IJRR 2017 best paper . [Paper] [Talk]
Differentiable Motion Planning
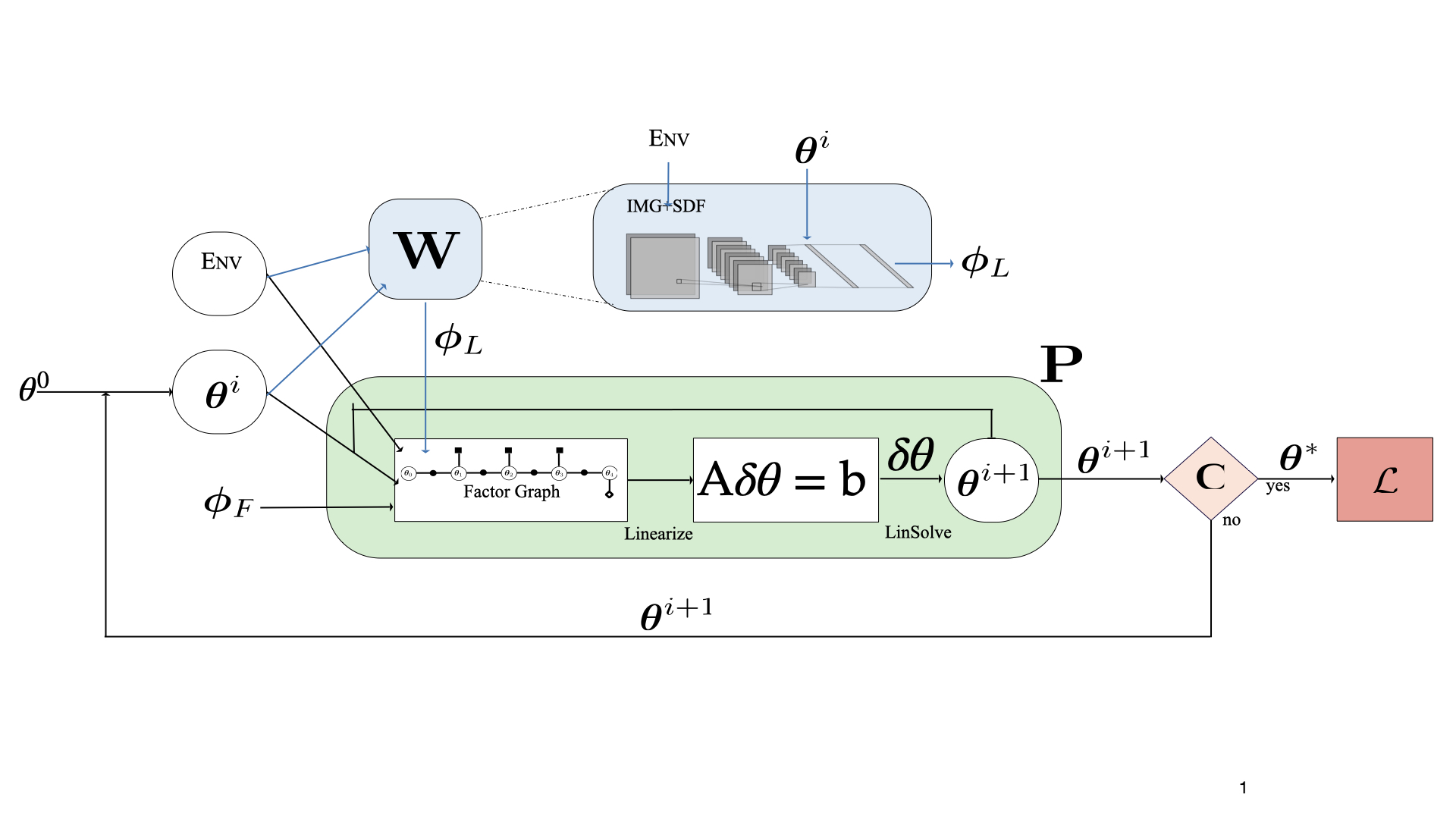
We propose a differentiable factor-graph based trajectory optimization algorithm that can be trained end-to-end in a self-supervised fashion. Published at ICRA 2021. [Paper][Talk]